PlaceboBench: An LLM Hallucination Benchmark for Pharma
We created PlaceboBench, a challenging pharmaceutical RAG benchmark based on real clinical questions and official EMA documents. Twelve state-of-the-art LLMs show hallucination rates between 24% and 64%.
Updated: This post has been updated with results from five additional models: GPT 5.4, GPT 5.4 Mini, Gemini 3.1 Pro, Gemini 3.1 Flash Lite, and Claude Sonnet 4.6.
Intro
Most LLM applications operate within a specific domain: legal, financial, medical, insurance. Yet the benchmarks we use to evaluate these models are often generic. To understand how well an LLM performs in a given field, we need domain-specific evaluation. For retrieval-augmented generation (RAG) in the pharmaceutical domain, no groundedness or hallucination benchmark exists.
Hallucinations have not gone away. As LLMs have improved in fluency, hallucinations have become even more difficult to spot, but not less frequent.
A placebo is an inactive treatment or substance that has no therapeutic effect on its own, but is designed to look like a real medical treatment. LLM hallucinations share this characteristic with placebos: they're presented with the same appearance of authenticity as real information, oftentimes making them indistinguishable to the recipient.
We created PlaceboBench, a challenging pharmaceutical RAG benchmark based on real clinical questions and official European Medicines Agency (EMA) documents. We ran twelve state-of-the-art LLMs on it: Gemini 3 Pro, Gemini 3 Flash, Gemini 3.1 Pro, and Gemini 3.1 Flash Lite from Google; Claude Opus 4.6, Claude Sonnet 4.5, and Claude Sonnet 4.6 from Anthropic; GPT 5.2, GPT 5 Mini, GPT 5.4, and GPT 5.4 Mini from OpenAI; and Kimi K2.5 as an open-source alternative. We observe hallucination rates between 24% and 64%.
Why create a new benchmark?
After analyzing existing hallucination benchmarks, we identified issues that make most of them a poor fit for benchmarking real-world agent and RAG systems in 2026.
1. Many hallucination benchmarks are too easy
Summarizing a 600-word news article into a 100-word abstract is too easy for current-generation LLMs. Answering a simple question based on three 200 word chunks does not reflect the complexity we have seen when implementing RAG applications for dozens of customers across many industries.
2. Existing benchmarks use stale data
Benchmarks like RAGTruth or FaithBench use tasks from NLP datasets like CNN / Daily Mail (published in 2016), MSMarco (published in 2016) or XSUM (published in 2018). These datasets were adequate for benchmarking NLP models at the time of their publication, but they should not be used to benchmark current models. One issue is data leakage. It is almost certain that existing models have seen all, or parts of these benchmarks during pretraining. If benchmark data has leaked into the training data, a model's score will not reflect its true performance.
3. Some benchmarks fabricate failure scenarios
To elicit higher hallucination rates, some benchmarks alter data or use synthetic data to make tasks more challenging. The FaithBench authors state that "some passages are specifically crafted to 'trick' LLMs into hallucinating" (Bao et al.). LibreEval uses LLMs to generate questions. For 18 percent of the dataset, they prompted the model to generate questions asking for information that is not provided in the context, or questions that are not solvable, contain errors, or contradictions. The danger with introducing these artificial challenges is that they might not reflect realistic failure patterns and thus lead to a benchmark that has poor applicability for real-world tasks. In our experience, models hallucinate plenty when used in realistic RAG scenarios, so we don't see the need to introduce synthetic opportunities for failure.
4. There are few domain specific benchmarks
RAGTruth uses CNN/Daily Mail as well as questions about 'daily life' from the MSMarco dataset. Aggrefact uses datasets from several news corpora, Wikipedia, the ELI5-subreddit, WikiHow, and more. HalluRAG uses Wikipedia. There is a bias towards news corpora and generally available web data in existing hallucination benchmarks. We could not find many hallucination benchmark that uses tasks matching use cases that companies around the globe are currently trying to implement with generative AI.
We applied the following criteria when creating PlaceboBench:
- Use challenging tasks that reflect real-world use of generative AI
- Propose novel tasks not previously used in other benchmarks
- No synthetic data, no synthetic queries, no fabricated failure scenarios
- Apply an industry-standard RAG setting so that observed hallucination rates are indicative of what AI engineering teams see in practice
- Domain-specific data and a use case verified with companies and organizations working in that domain
Dataset
Dataset creation
We chose the pharmaceutical domain for this benchmark because it combines two critical characteristics: heavy reliance on complex, text-dense technical documents, and low tolerance for inaccurate information. In healthcare settings, hallucinated medical information can directly impact patient safety, making this an ideal domain to test LLM reliability. The benchmark task is also grounded in practice: we have worked with a client in the pharmaceutical industry on a comparable question-answering system over regulatory documents.
We found SVELIC, a platform run by Sweden's regional drug information centers in collaboration with Norway's drug information center RELIS.
SVELIC maintains a public database of real clinical questions that Swedish and Norwegian healthcare professionals have submitted to their regional drug information centers about the admission of drugs, interactions with other active ingredients, dosing in special populations, etc. For our benchmark, we extracted 69 questions spanning 23 different drugs, and machine-translated them to English.
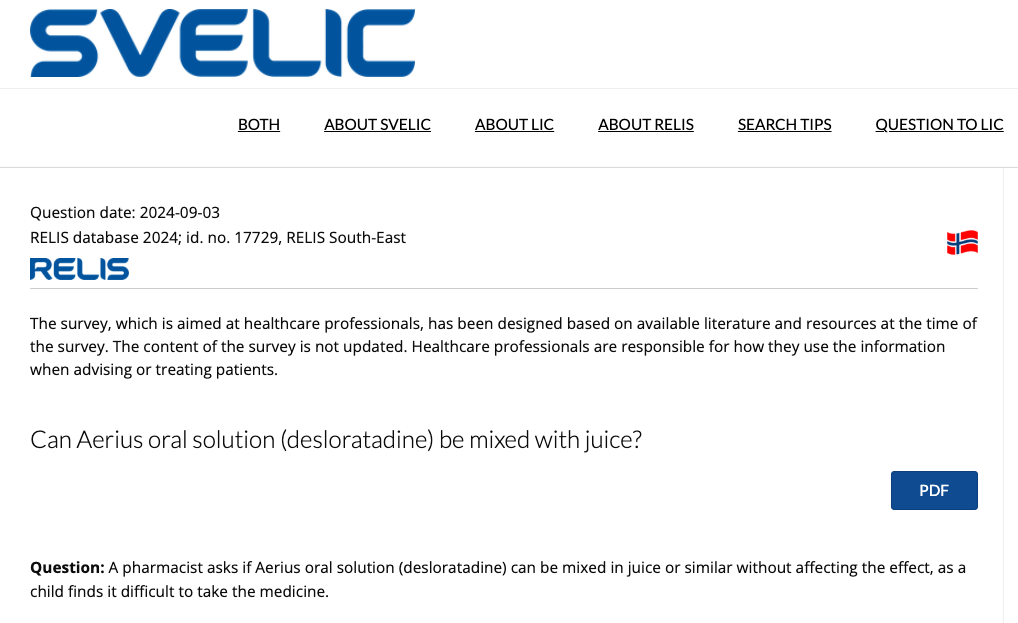
Example of a clinical question from the SVELIC database.
For ground truth, we used the Product Information documents of 2156 drugs published by the European Medicines Agency (EMA, Download), including the documents on the 23 drugs referenced in our question set.
EMA Product Information for each drug includes two documents: the patient information leaflet and the Summary of Product Characteristics (SmPC). SmPCs are the official regulatory documents containing comprehensive pharmaceutical information for healthcare professionals. They include all information needed to prescribe and use medications safely: contraindications, dosing guidance, drug interactions, side effects, and pharmacological properties. While patient leaflets are written for a lay audience, SmPCs are technical documents intended for medical professionals.
Here's an excerpt of the SmPC of the drug Aerius:

Excerpt from the Summary of Product Characteristics (SmPC) for the drug Aerius.
All Product Information documents follow a strict standardized template mandated by the EMA. They contain primarily plain text with tables, particularly for adverse effects and their frequency classifications, and they can contain graphs. They're distributed as PDFs with up to 608 pages depending on how many formulations or strengths are covered in a single document. The median length is 42 pages.
Evaluation Process
LLM Selection
We selected twelve state-of-the-art LLMs that represent what organizations actually deploy in production environments today.
From each major provider, we tested their most recent flagship models as well as their more cost-efficient alternatives. This includes Gemini 3 Pro, Gemini 3 Flash, Gemini 3.1 Pro, and Gemini 3.1 Flash Lite from Google, Claude Opus 4.6, Claude Sonnet 4.5, and Claude Sonnet 4.6 from Anthropic, and GPT 5.2, GPT 5 Mini, GPT 5.4, and GPT 5.4 Mini from OpenAI. We also included Kimi K2.5 as an open-source option to compare against the proprietary models.
The models span a wide pricing and latency spectrum as well. This range lets us evaluate whether higher costs or latency correlate with lower hallucination rates in pharmaceutical question answering. The selection covers the typical decision space developers face when building RAG or agent systems: trading off between maximum capability and cost efficiency.
RAG Pipeline
To create the question-answer datasets, we used a retrieval-augmented generation (RAG) pipeline. We processed the Product Information PDFs through three steps:
- PDF Conversion: Extract text from the SmPC PDFs
- Document Splitting: Break each Product Information into overlapping chunks of 300 words (with 30-word overlap), resulting in a total of 131,467 document chunks
- Embedding and storage: Convert each chunk into a 768-dimensional vector using Google's embeddinggemma-300m, and store it in a vector database (Qdrant)
The metadata from each Product Information document (including product name, approval dates, etc.) is attached to every chunk, allowing us to trace retrieved passages back to their source document.
Now each of the 69 SVELIC queries goes through the following steps of the query pipeline:
- Query Embedding: Vectorize the query using the same model used for indexing
- Retrieval with top_k=10: Search Qdrant for the top 10 most similar document chunks
- Window Expansion: For each retrieved chunk, also fetch the neighboring chunks (1 before and 1 after) to provide context around the relevant passages
- Prompt Construction: Group the retrieved chunks by pharmaceutical product and format them into a structured prompt. The median number of input tokens to the LLM was 13,668. The system prompt instructs the LLM, among other things, to:
- Answer based strictly on provided documents (no external knowledge)
- Keep responses concise (1-2 paragraphs)
- Use precise medical terminology from the source documents
- Generation: The LLM generates the final answer
Annotation Process
We began by running the RAG pipeline using Kimi K2.5 as the first model. We integrated Blue Guardrails into the pipeline to automatically sync all traces (i.e. retrieved documents, prompts, and LLM responses), to the Blue Guardrails platform.
The Blue Guardrails platform gives annotators a unified view of each trace: the user query, the retrieved document chunks with their metadata, and the LLM's response side by side. Crucially, our annotations operate at the claim level, not the message level. Rather than labeling an entire response as "hallucinated" or "faithful," we select the exact span of text that contains an error and categorize it individually. This allows us to identify exactly where and how a model fails within a single response.
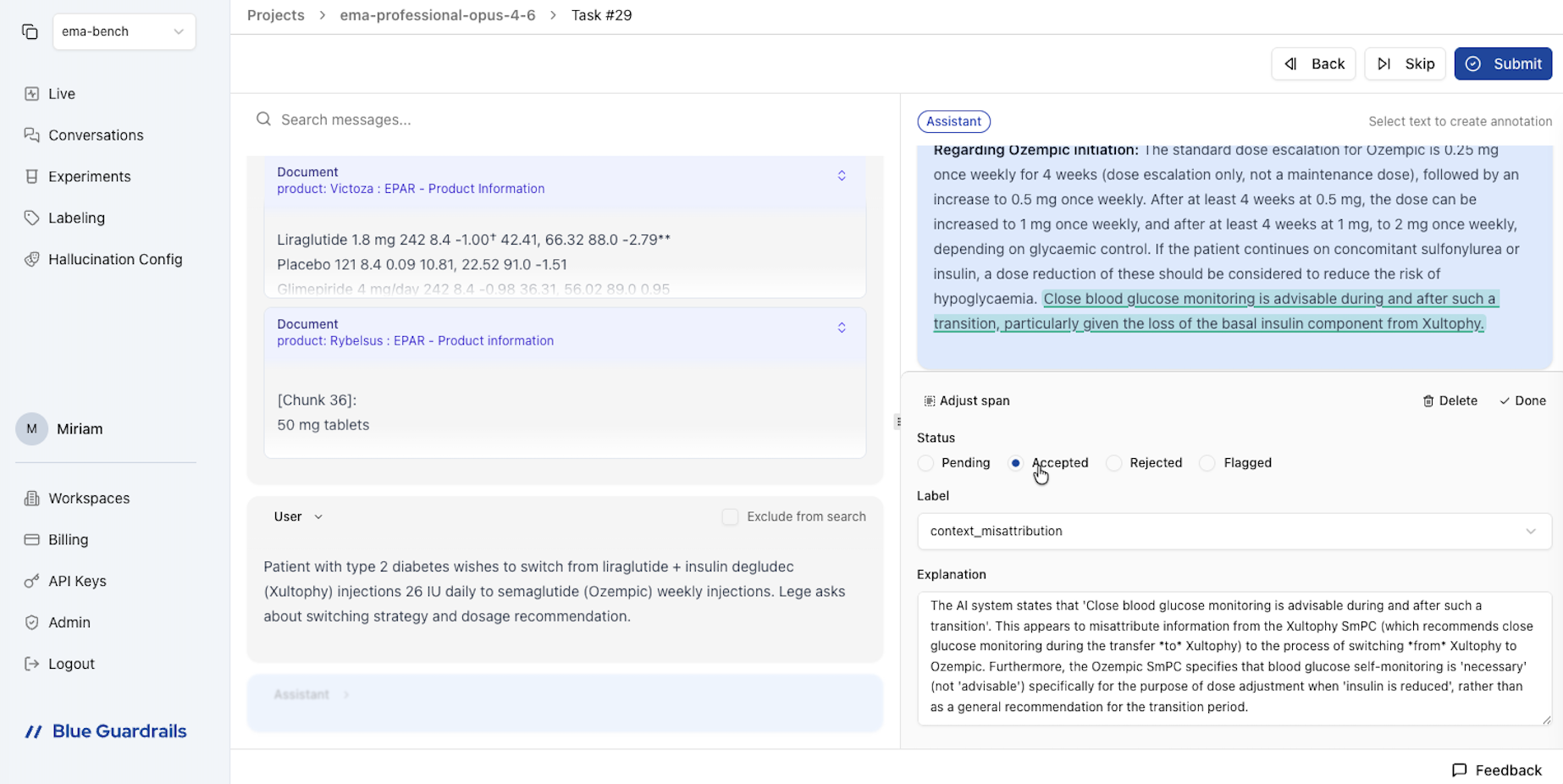
The Blue Guardrails platform provides a unified view of each trace for claim-level annotation.
We applied our automated hallucination detection method to the collected data. We then manually reviewed each flagged instance, correcting false positives and adding any hallucinations the algorithm missed. Our annotation used eight categories:
After completing the annotation for Kimi K2.5, we ran the same contexts and prompts through the six remaining models. Again, we applied the hallucination detection algorithm to each model's outputs and performed manual annotation using the same eight-category framework.
As a quality control measure, all annotations were reviewed by a second annotator. This double-annotation process ensured consistency and reliability across our dataset.
Results
We measure hallucination rate as the percentage of model responses that contain at least one hallucinated claim. Hallucination rates range from 24.2% to 63.8%. GPT 5.4 has the lowest hallucination rate and Claude Opus 4.6 the highest. For Google's first-generation Gemini 3 models and OpenAI's GPT 5 series, flagship models outperform their cost-efficient counterparts. However, this pattern does not hold for Anthropic (both Sonnet versions are better than Opus 4.6) or the Gemini 3.1 generation, where Gemini 3.1 Flash Lite achieves a lower hallucination rate than Gemini 3.1 Pro.
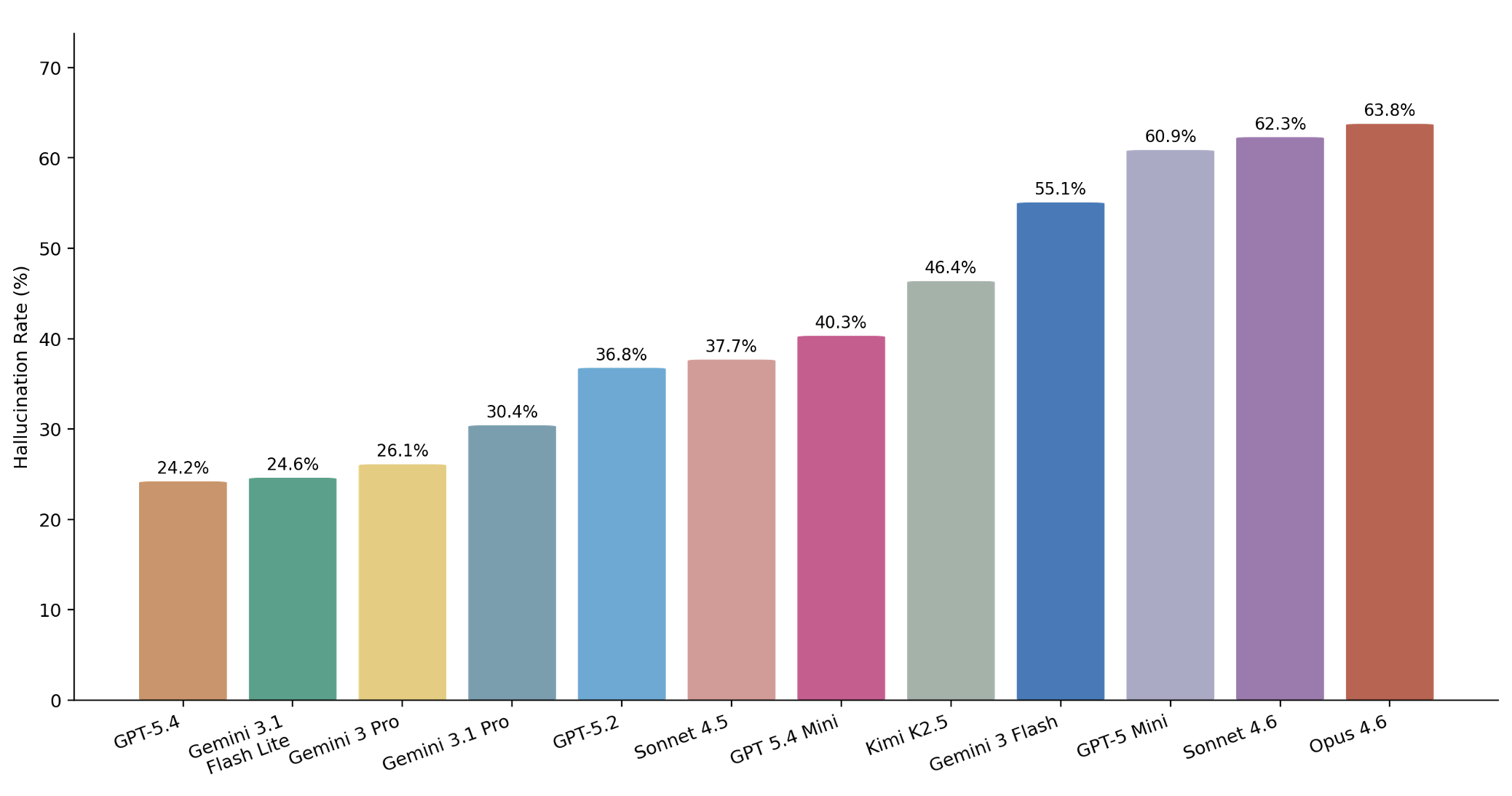
Hallucination rates across twelve LLMs on PlaceboBench. GPT 5.4 achieves the lowest rate (24.2%), while Claude Opus 4.6 has the highest (63.8%).
Hallucination type distributions provide insight into error patterns. Fabricated claims are the most frequent source of hallucinations overall, and world knowledge errors are the second-most frequent category. Many models frequently insert pharmaceutical or medical knowledge from pretraining rather than restricting answers to the retrieved context, despite explicit instructions not to.
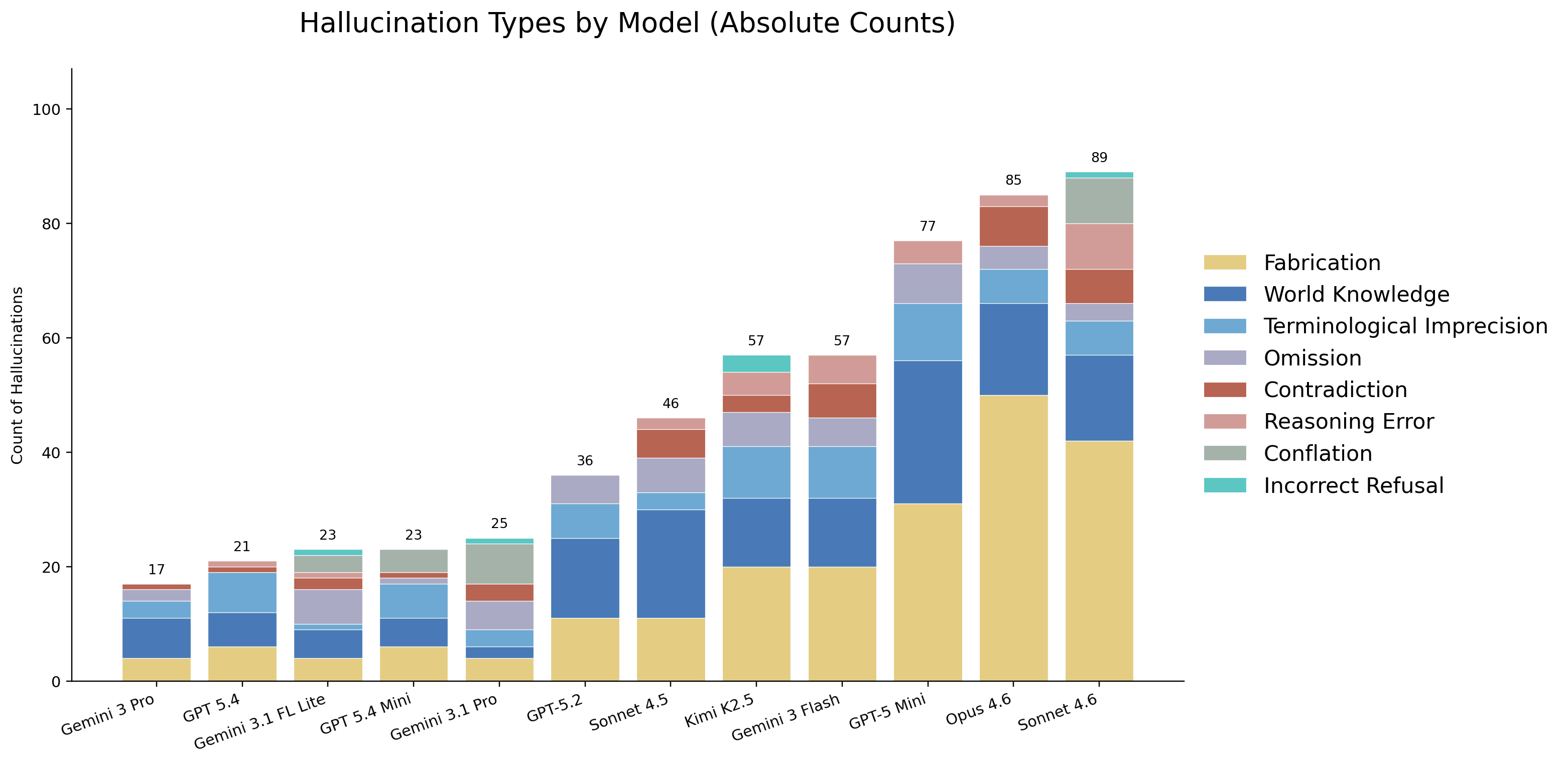
Distribution of hallucination types across models. Fabrication and world knowledge dominate overall, though patterns vary across models.
The charts below report costs and latencies for each model. We calculate how much it would cost to run 1,000 prompts like the ones we used in the benchmark, based on actual observed costs. Kimi K2.5 was used through the serverless inference offering from Fireworks. Pricing for other vendors might differ.

Cost per 1,000 prompts and average request latency for each model.
GPT 5.4 is the most expensive model we benchmarked, at $94.21 per 1,000 prompts. Gemini 3.1 Flash Lite is the most affordable option in our model selection, at $5.68 per 1,000 prompts.
We measure latency for each request and report the average request latency for each model. Anthropic models were used through the Anthropic API, OpenAI models through the OpenAI API, Google models through the Google AI Studio API, and Kimi K2.5 through the Fireworks API. Latencies may differ depending on location, time of day, or quota tier. GPT 5.4 has the highest average latency in our tests, and Gemini 3.1 Flash Lite the lowest.
We attribute the differences in latency mostly to the number of thinking tokens each model produced. The median number of response tokens and thinking tokens varies significantly across models. Response lengths are roughly comparable across models, though Opus 4.6 produces slightly longer responses.

Median response and thinking token counts per model. Opus 4.6 and Sonnet 4.6 use the fewest thinking tokens, while GPT 5.4 Mini uses the most (6,834).
Despite all models being tested with high or extra-high reasoning effort parameters, Opus 4.6 and Sonnet 4.6 use the fewest thinking tokens, with medians of just 353 and 417 respectively. OpenAI models generate the most reasoning tokens overall, with GPT 5.4 Mini reaching a median of 6,834 thinking tokens per response.
Discussion
Hallucinations are clearly still an issue in the latest LLMs. All models showed hallucination rates higher than what would be acceptable for most use cases, particularly in a sensitive domain like pharma.
At the same time, hallucination rates differ meaningfully between SOTA models and are not necessarily correlated with general benchmark performance. Teams building agents or RAG applications need to run their own evaluations to reliably pick the best model and configuration for their use case.
What surprised us most is the performance of Opus 4.6 on our benchmark. The model is one of the most capable coding models and ranks at the top of many leaderboards. Yet it fails on our task. One explanation might be its low use of reasoning tokens before generating a response. An observation that supports this hypothesis, not included in the main results, is a benchmark run with Claude Sonnet 4.5 with and without reasoning enabled. With reasoning enabled, Sonnet hallucinates at a rate of 39.5%. With reasoning disabled, that rate jumps to 87% on the same data. Note that the run without reasoning did not go through human review, the 87% figure is based solely on the AI-predicted hallucination rate. For all other models, the human-reviewed rate only differed by a few percentage points from the AI-predicted rate.
Looking at individual hallucinations, not all are equally bad. Some may even be desirable depending on the use case. Most instances of world knowledge likely fall under that category. Models expanding abbreviations or explaining technical terms can be very helpful. However, this comes with increased risk, as the added information may be wrong or inappropriate for the specific context.
Opus 4.6 often suggested clinical protocols for monitoring of patients or performing clinical tests. These suggestions were not grounded directly in the retrieved product information. While they could be inferred from the product information, medical professionals would need to assess whether they are appropriate for each individual case. Every team needs to assess whether liberal inferences from the model fit their risk appetite. From our work with pharmaceutical clients we know that the risk profile for this use case mandates a strict prohibition of such inferences.
While the acceptability of some hallucinations may depend on the use case, a large share are clearly unacceptable regardless. As shown in the example below, models frequently reported incorrect frequencies for side effects. Reporting a rare side effect as common, or vice versa, can severely impact clinical decision-making.

A model incorrectly reported the frequency of a side effect, confusing rare and common classifications.
All models frequently conflated information from the retrieved context. A common pattern is generalization. As shown in the example below, a specific dose interruption scheme was mentioned for only one indication, and the model generalized it to all treated conditions. The same pattern appeared when generalizing observations for a special population (e.g., young or elderly patients) to all patients.

A dose interruption scheme specific to one indication was generalized by the model to all treated conditions.
For end-to-end RAG evaluations, the rate of omissions is likely higher than what we report here. Since we only evaluated the retrieved context, we only labeled cases where the model omitted information that was in fact retrieved and relevant to the question. Teams building RAG applications should add evaluations that cover retrieval as well (e.g., a recall metric).
Another key observation is that hallucinations are very hard to spot. Reviewing a single response took between 10 and 20 minutes. The volume of input data is a major challenge. The median number of input tokens per response is 13,000 (roughly 10 to 20 pages of text to review). Hallucinations were rarely obvious from reading the model response alone. A typical response reads as fluent, coherent, and well-grounded. Only deep analysis (or subject matter expertise) uncovers the underlying hallucination rate. Reviewing AI-generated content superficially can easily lead to incorrect assumptions about the hallucination rates of current-generation models.
Conclusion
PlaceboBench shows that state-of-the-art LLMs still hallucinate at high rates when evaluated on novel, challenging tasks with strict groundedness requirements. On our pharmaceutical RAG benchmark, hallucination rates range from 24% (GPT 5.4) to 64% (Claude Opus 4.6). The tasks aren't adversarial or edge cases, they are realistic questions from healthcare professionals, answered using official regulatory documents in a standard RAG setup.
The results also show that general-purpose benchmark performance does not predict domain-specific reliability. Opus 4.6, one of the highest-ranked models on coding and reasoning leaderboards, produced the highest hallucination rate in our evaluation. GPT 5.4, on the other hand, achieved the lowest hallucination rate, though at the highest cost in our selection.
Frontier models are often treated as interchangeable, but our results show meaningful differences in capabilities. Model selection has a large impact on AI application quality, and AI engineering teams should run systematic evaluations on their own data when making model choices.
High hallucination rates call into question whether generative language models are an appropriate fit for high-risk business processes. Many tasks in legal, insurance, healthcare, and other domains have extremely strict groundedness and accuracy requirements. We are optimistic about the use of LLMs in these domains, but any team implementing an AI solution must pair rigorous evaluation with intelligent post-deployment monitoring and appropriate guardrails.
PlaceboBench is available on Hugging Face.
Want to benchmark your own use case?
Would you like to receive more content like this?
Subscribe to our email list

