What does it cost to do OCR with Large Language Models?
Our LLM OCR Cost Calculator allows AI builders to compare PDF parsing costs across different LLM providers and models
TL;DR:
- We are introducing our LLM OCR Cost Calculator allowing you to compare PDF parsing costs across different LLMs
- The calculator accounts for differences in tokenization and source material (like tables or charts) for more accurate pricing estimates
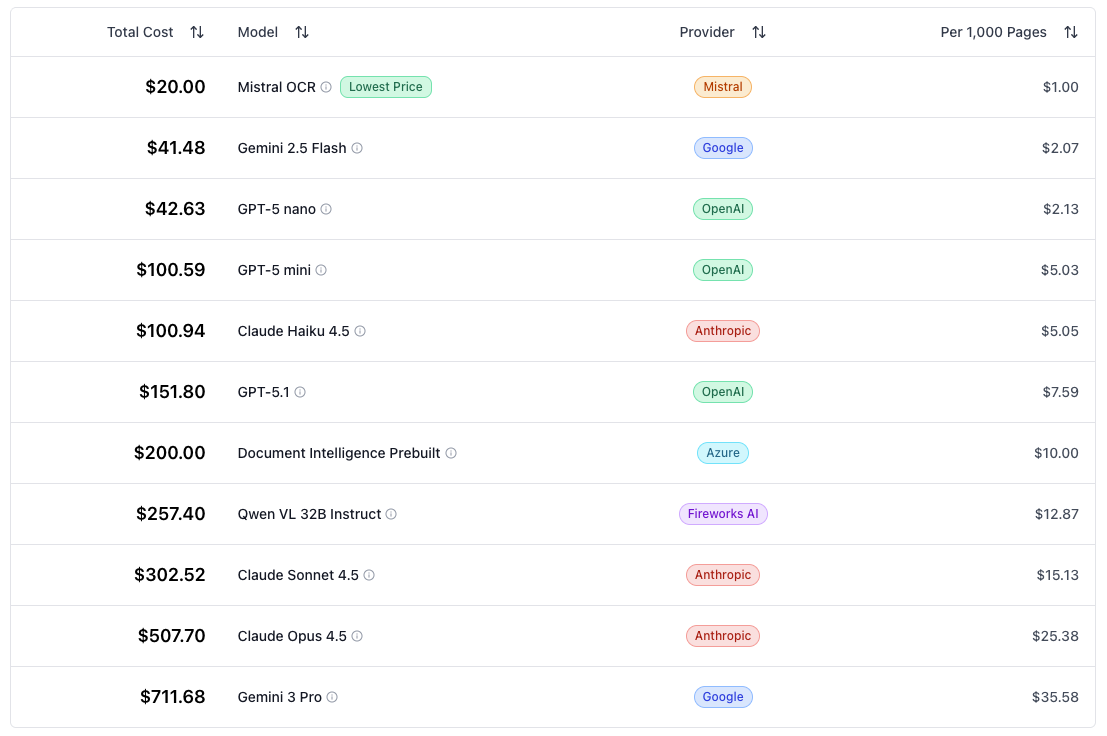
Compare OCR costs across providers with our
LLM OCR Cost Calculator
Anyone who has ever dealt with extracting content from PDF documents knows that it is an inexplicably cumbersome process. Standard PDF-conversion-tools often come with a myriad of problems, such as garbled text output, wrongly parsed multi-column layouts, or missing tables and charts.
At the same time, parsing PDF files is still a major need in business. Any RAG implementation for internal knowledge management needs to use PDF files. An AI workflow automating claims management in insurance needs to parse them. An agent assisting lawyers with legal research gets most of its information from PDF sources.
Vision LLMs solve many of the problems with traditional PDF parsing tools. They produce beautifully formatted output, even for complex layouts. They can extract information from charts and turn it into text. Even hand-written comments or annotations present no issue at all.
We often reach for vision LLMs when dealing with PDF files because their superior parsing performance enables better AI applications down the line. Among other things, higher quality document extraction leads to fewer hallucinations in RAG applications and agents.
One concern with using LLMs for document extraction is the price. For every large extraction job, we ended up wondering what it would cost us. How much do we need to pay for a thousand pages? What if our PDF documents contain many tables or charts? Which model is cheapest?
Answering these questions can be surprisingly time consuming.
PDF pages are passed as images to the vision LLM API. From there, a tokenizer slices up the image into little patches so that the model can process them. This tokenization step produces a different number of input tokens, depending on the resolution of the image and the specific tokenizer used. The number of input tokens is important, because model providers typically bill per input token.
From those sliced up image patches, the model generates text. Depending on the prompt, it can apply different formatting and describe charts or images. Text too can be measured in tokens. Output tokens are typically more expensive than input tokens, because the model needs more GPU capacity for writing compared to reading. Depending on the tokenizer, the same text can translate to a different amount of output tokens. A five word sentence might translate to 15 tokens for one model, while it yields 20 tokens for another.
For obvious reasons, output tokens also depend on the type of document we are parsing. An annual report with many charts and tables might produce less tokens per page than a densely formatted academic paper with a two-column layout.
For our OCR Calculator, we took all these factors into consideration.
We prepared two extraction scenarios:
- A mixed content annual report with charts and tables
- An academic paper with minimal formatting and a two-column layout
We ran 10 pages of our sample documents through each LLM and recorded the median amount of input and output tokens per page. Then, we plugged these numbers into our calculator as the basis of the per page cost estimation.
This can lead to surprising results:
OpenAI charges $0.05 per 1 Million input tokens and $0.40 per 1 Million output tokens for its GPT-5 nano model. Gemini Flash 2.5 from Google costs $0.3 and $2.5 per input and output tokens respectively. Still, for some scenarios Gemini Flash ends up being cheaper than GPT-5 nano because it uses less tokens per page.
We are releasing the calculator as a free mini-application for AI builders. Any time you are wondering about the costs of a PDF extraction job, you now have a place to turn to. We'll update the app over time and we're always happy about feedback!
