Why Hallucination Benchmarks Miss the Mark
The gap between hallucination benchmarks and production reality and what bears have to do with it
TL;DR:
- Current hallucination benchmarks use unrealistically simple RAG setups
- Production systems are far more complex: more and longer documents, sophisticated context engineering, domain-specific tasks
- Benchmark performance doesn't predict real-world performance
Benchmark datasets are an important tool across research areas. They enable researchers and practitioners to measure model performance in a standardized manner. This also applies to Generative AI, and in particular hallucination detection: How capable is an algorithm of detecting hallucinations in outputs of LLM applications like Agents and RAG (Retrieval-Augmented Generation) applications?
To measure that, the datapoints in hallucination benchmark datasets are usually comprised of three things:
-
The query that was sent to the LLM application. It contains the user query and/or the system prompt containing a certain task for the LLM application to solve, and the context the LLM was given. If it's a RAG or a summarization setup, the context is made up by a certain number of document chunks ("passages"), like the following:
Briefly answer the following question: butcher shop phone number Bear in mind that your response should be strictly based on the following three passages: passage 1:Butcher Shop - Hayward 826 B Street, Hayward CA 94541 Phone Number: (510) 889-8690
passage 2:Butcher Shop - Lakefield 212 Main Street, Lakefield MN 56150 Phone Number: (507) 662-6281
passage 3:Some More Phone Numbers Related To The Butcher Shop The Local Butcher Shop phone number : (510) 845-6328 Boones Butcher Shop phone number : (502) 348-3668 Ye Ole Butcher Shop phone number : (972) 423-1848 J Ms Butcher Shop phone number : (865) 483-9228
In case the passages do not contain the necessary information to answer the question, please reply with: "Unable to answer based on given passages."
-
The response of the LLM application:
Based on the given passages, there are several different phone numbers associated with butcher shops. However, none of them are for a specific location named "bear" or have any indication of being related to bears. Therefore, it is unable to determine if there is a butcher shop phone number specifically for "bear".
-
The annotations, aka. the spans in which hallucinations were detected, and some context information on them: a label of severity or type of hallucination, reasoning or explanation on why it is considered a hallucination ("meta"), and the model that generated this output
{ "text": "However, none of them are for a specific location named 'bear' or have any indication of being related to bears.", "label_type": "Evident Baseless Info", "meta": "HIGH INTRO OF NEW INFO No mention of this in the passages and original answer.", "model": "mistral-7B-instruct" }
Modern LLMs would likely not make this mistake anymore, but it's a clear example of hallucination: the prompt asks the LLM to "bear in mind that...", and the interpreting LLM (mistral-7B-instruct) confuses the idiom with the animal.
Now these annotations (together with a few hundred more in the same vein) will function as a ground truth: Anyone developing hallucination detection algorithms can use the dataset to objectively test the performance of their hallucination detection method. If their detection algorithm finds every one of the annotated hallucinations, and on top of that, does not claim any spans being hallucinations that were not annotated, their F1 score on this specific benchmark will be 1, or 100%. F1 is a popular performance metric in evaluating classification tasks, as it captures both the ability to find hallucinations (→ high recall) and to avoid false alarms (→ high precision).
One out of several important prerequisites for this assessment to be reliable is that the benchmarking data needs to depict realistic environments in which LLM applications are utilized. If you test your detection method on scenarios that will not occur "in the wild" you did not learn anything about the performance of your algorithm "in the wild".
And this is where the trouble starts.
When we started developing our own hallucination detection methods, we were looking for benchmarks to test them on, and found RAGTruth (published 2024, by ParticleMedia) and FaithBench (published 2025, by Vectara).
RAGTruth's data comes from three different task categories (Question Answering, Data2Text, Summarization), amounting to almost 18.000 datapoints. It is one of the most popular hallucination benchmarks at this point, for good reasons: it includes high-quality and labor intensive manual annotations, and uses "natural" hallucinations that are not artificially prompted for. The "butcher shop" example above is from RAGTruth.
FaithBench, on the other hand, covers 750 summarization cases where several hallucination detection approaches (like utilizing GPT-4o, or Vectara's HHEM-2.1) disagreed with each other. This makes for a more challenging benchmark for other detection methods. Some hallucinations were artificially induced by prompting the LLM to hallucinate. Again, the annotations were carefully done by human annotators. Here's an example from FaithBench:
source:
"Poseidon (film) . Poseidon grossed $ 181,674,817 at the worldwide box office on a budget of $ 160 million ."
summary:
"The film "Poseidon" grossed $181,674,817 at the worldwide box office, with a production budget of $160 million."
annotations:
{
"text": "production",
"label_type": "Unwanted.Intrinsic",
"meta": "budget (source) vs. production budget (summary): The budget for a movie may also include non-production budget such as distribution, advertising.",
"model": "mistralai/Mistral-7B-Instruct-v0.3"
}RAGTruth and FaithBench are valuable contributions that represent significant annotation effort and provide researchers with important starting points. The teams that built them likely faced constraints like limited access to production systems, budget and time limitations, and the challenge of creating generalizable datasets in an academic setting. These benchmarks were never designed to perfectly replicate every production environment. Our point is not that they're poorly made, but that a fundamental gap exists between what standardized benchmarks can capture and what matters when AI creates real value.
That said, when we're trying to assess the performance of real-life LLM applications, both benchmarks share two larger areas of issues:
1. The RAG setup as a whole is unrealistic
The setup of the queries is simple. For the QA-tasks in RAGTruth they passed three very short snippets of text along with a short user query. The length of the snippets are mostly a few sentences.
Looking at both datasets, and the lengths of their prompts (i.e. inputs to the applications), we find that RAGTruth's median length of prompts is 550 tokens, and FaithBench's is only 223. As the histogram below shows, most prompts in both benchmarks are far shorter than what production systems typically use.
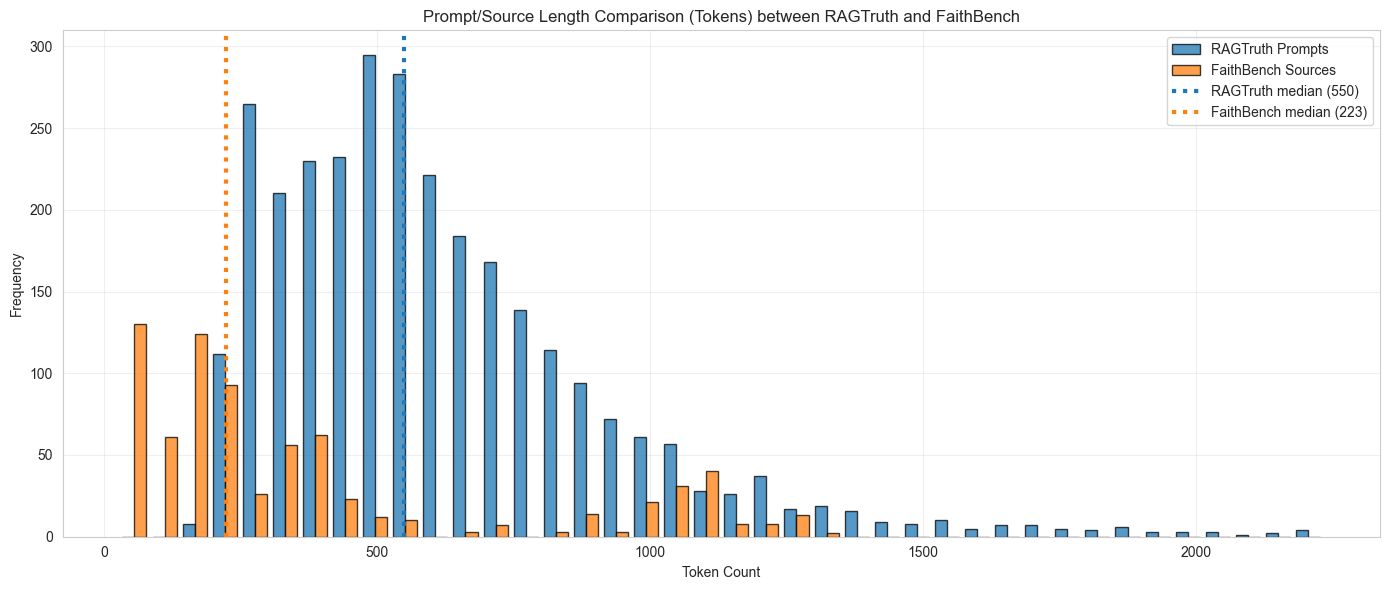
Very few queries out there would best be served by passing a top-k of 3 (top-k being the number of document chunks passed to the LLM application), especially when the chunks are so short. Either you would not use a RAG setup at all, or the top-k would be much larger than 3. If the top-k was really 3, the snippets would be much larger. The models used in creating RAGTruth and FaithBench range in context length from 4,096 tokens (e.g., llama-2-70b-chat) to one million tokens (google/gemini-1.5-flash-001), so there was no technical constraint forcing such limited context.
Simple, "everyday" information-seeking questions, like "What is the difference between a rock and a stone" (RAGTruth) would best be answered utilizing the trained world knowledge of an LLM, not any retrieved information sources.
If the query was more intricate, and therefore warrant the usage of a RAG setup, one would likely pass many more documents to adequately answer it, or at least pass much longer text snippets.
Briefly answer the following question: what is the difference between a rock and a stone
Bear in mind that your response should be strictly based on the following three passages:
passage 1:More common than death by stone is the affirmation of a Holy Being as the "rock of one's salvation." This sense highlights a central difference between the words. People often use rock to refer to something solid, large, grounded, substantial, something to base your faith upon, such as a mountain or palisade. refer to the two icons of that theater, The Rock and Stone Cold Steve Austin. Surely these two men illustrate the differences between the two words. Ultimately, I have concluded that there is some difference between the terms. I agree with Thorson that stone more often implies some sort of human use.
passage 2:Rocks vs Stones. Although most of us confuse rocks and stones and consider them as the same, there exists a clear difference between rocks and stones. First let us define the two words. A rock is the hard material of the earth's crust. It is normally exposed on the surface of the earth or sometimes underlying the soil.ocks vs Stones. Although most of us confuse rocks and stones and consider them as the same, there exists a clear difference between rocks and stones. First let us define the two words. A rock is the hard material of the earth's crust. It is normally exposed on the surface of the earth or sometimes underlying the soil.
passage 3:Summary. 1. Rocks are made of smaller stones and stones are made from rocks. 2. Rock can be described as a large piece of stone that is difficult to be carried in the hand. On the other hand, stone is just a small piece or pebble that can be carried in the hand. 3.The stones can be pelted easily but one cannot do so with rocks.. Rocks are made of smaller stones and stones are made from rocks. 2. Rock can be described as a large piece of stone that is difficult to be carried in the hand. On the other hand, stone is just a small piece or pebble that can be carried in the hand. 3. The stones can be pelted easily but one cannot do so with rocks.
In case the passages do not contain the necessary information to answer the question, please reply with: "Unable to answer based on given passages."
Based on the passages, rocks refer to something solid, large, and grounded, often part of the earth's crust and sometimes exposed on the surface or underlying the soil. Rocks are made up of smaller stones. On the other hand, a stone is typically a small piece or pebble that can be carried in the hand. Stones are often associated with human use.
Not only is the RAG setup itself unrealistic, the data characteristics are also less complex than actual problem-solving RAG setups. The source data contains very straight-forward and easy-to-understand text. The user queries lack domain-specific information needs and don't reflect the sophisticated human workflows needed to solve intricate tasks.
Real-world applications look different
The real-life, value-generating Agents and RAG applications we've seen in the industry utilized various data formats: text, messy html, tables, PDFs, SQL databases, different documents superseding each other. Often they'd include domain-specific jargon that's much less represented in LLMs' training data than everyday English. The context in most cases was large: passing between 10k to 80k tokens distributed across 15 to 50 document chunks was the norm. Additionally, the prompts we developed required different prompting approaches like chain-of-thought-prompting, zero- or few-shot-prompting, prompt-chaining, and oftentimes format enforcement (e.g. json or SQL). The intricate ways of working of legal professionals, credit scorers, journalists, as well as their typical language usage, had to be carefully replicated in order to elicit LLM responses that provide business value to the user.
2. The tasks for the LLM applications are oversimple
The hallucinations that matter in production are those that lead to wrong decisions: incorrect legal advice, flawed financial assessments, or misleading information that erodes user trust.
Generally speaking, summarization and QA are realistic and important capabilities of LLM applications, but they rarely serve as ends in themselves, and certainly not when paired with overly simple context data.
Summarizing a very short news article "within 25 words" (RAGTruth), or describing the difference between a rock and a stone, given 3 short text snippets are not realistic tasks that generate value.

LLM applications we've seen were:
- a RAG chat setup tasked to answer queries on the creditworthiness of businesses in certain areas developing over time
- an agentic RAG setup assessing the applicability of a newly passed EU law on Austrian municipalities and the consequences on jurisdiction in a specific court case
- an AI workflow builder agent tasked to debug sophisticated AI pipeline setups
All of the use cases we've seen required some sort of summarization and/or question answering, but they went far beyond just that. Most notably, solving these tasks required sophisticated retrieval of carefully engineered data, a meticulously curated data composition for the LLM, and use case and domain specific context and prompt engineering. Solving these tasks via LLM applications generated value because the work the LLM application had to do in order to solve those tasks is utterly complex.
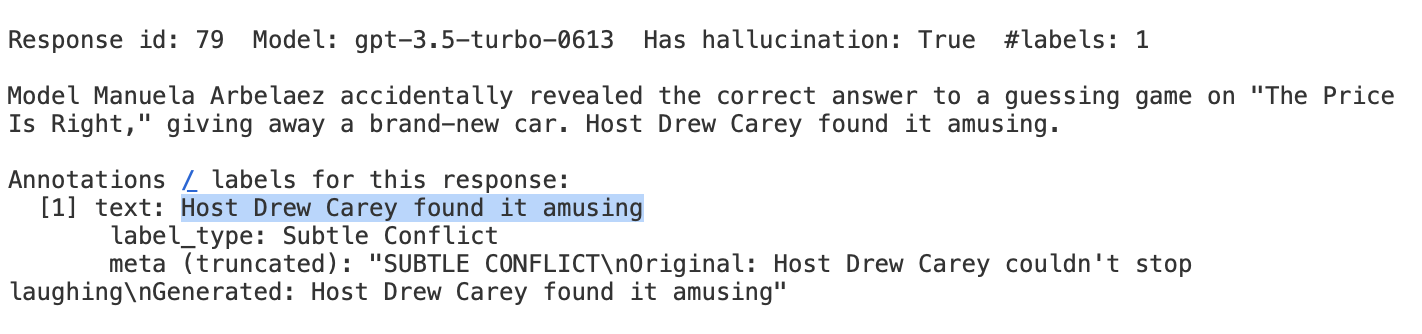
Saying someone "found it amusing" whereas in the original he "couldn't stop laughing" is clearly a hallucination and should be annotated and detected as such. But the whole input and output setup of this datapoint isn't representative of real-world challenges. A realistic hallucination is an agent analyzing the implications of a new legal regulation incorrectly and advising the application of federal law when state-level legislation should have governed the specific jurisdictional scenario.
Conclusion
Current hallucination benchmarks are not depicting the reality of how hallucinations are coming to be, how hard they are to spot, and how far their negative impact reaches. Therefore, even if AI systems perform well on these benchmarks, it tells us very little on how well they would perform on real life scenarios. The hallucinations that are showstoppers, that put AI applications at risk, that compromise work quality, are not the ones that were assessed in these benchmarks.
What we need are benchmarks that put the creation of value of LLM applications in real-life scenarios to the test. As we develop our own hallucination detection methods, we see this confirmed again: meaningful evaluation can only happen within the context where AI creates real value.
