RAGTruth++: Enhanced Hallucination Detection Benchmark
We enhanced the RAGTruth benchmark by finding 10x more hallucinations through automated detection and human review.
TL;DR:
- We significantly improved RAGTruth, a popular hallucination benchmark, uncovering 10x more hallucinations than the original annotations (86 to 865)
- Combined automated detection with systematic human review using our custom annotation tool Labelground
- Two annotators independently reviewed all 408 datapoints
- RAGTruth++ is now publicly available
Introduction
Hallucination detection and mitigation is one of the core challenges in building reliable AI systems. When LLMs generate content that isn't grounded in the provided context, they undermine trust and create real risks for organizations deploying these systems.
At Blue Guardrails, we wanted to evaluate our own hallucination detection methods. To do this, we started using RAGTruth (published in 2024 by ParticleMedia), and while looking into it, we realized quite a few of the hallucinations were not caught. The dataset had gaps that would make it hard to properly benchmark detection methods.
This led us to create RAGTruth++: an enhanced version of the RAGTruth benchmark dataset with more complete hallucination annotations. By combining automated detection with human review, we increased the number of identified hallucinations from 86 to 865: a tenfold improvement that makes this benchmark more useful for evaluating hallucination detection methods.
Better benchmarks enable better hallucination detection, which is critical for building trustworthy AI systems.
The Original RAGTruth Dataset
Dataset Overview
The original RAGTruth test set consists of 1,800 datapoints. For our enhancement project, we focused on 408 datapoints (a random selection of summary and QA tasks in the original RAGTruth benchmark dataset).
Datapoint Structure
Each datapoint in RAGTruth contains, among other data:
- The task type
- The model used to generate the answer
- The source of the query within the prompt
- The prompt
- The LLM's response
- The labels (annotations) of hallucination instances
Here's an example datapoint:
task_type: "Summary"
model: "llama-2-7b-chat"
source: "CNN/DM"
prompt: "Summarize the following news within 116 words:
Seventy years ago, Anne Frank died of typhus in a Nazi concentration camp at the age of 15. Just two weeks after her supposed death on March 31, 1945, the Bergen-Belsen concentration camp where she had been imprisoned was liberated -- timing that showed how close the Jewish diarist had been to surviving the Holocaust. But new research released by the Anne Frank House shows that Anne and her older sister, Margot Frank, died at least a month earlier than previously thought [...]"
response: "Here is a summary of the article in 115 words or less:
Anne Frank died of typhus in a Nazi concentration camp at age 15, two weeks after her supposed death on March 31, 1945. New research suggests that she and her sister Margot likely died at least a month earlier, contradicting previous estimates. The sisters were sent to the Bergen-Belsen camp in Germany after being arrested in Amsterdam in 1944. They endured harsh conditions, including lack of lighting, water, and sanitation, and were exposed to typhus due to poor hygiene. Witnesses reported that Anne and Margot exhibited symptoms before February 7, leading researchers to conclude that they likely died before March. Despite this, Anne's diary remains a powerful symbol of hope and resilience."
annotations: [
{
"start": 693,
"end": 754,
"text": "Anne's diary remains a powerful symbol of hope and resilience",
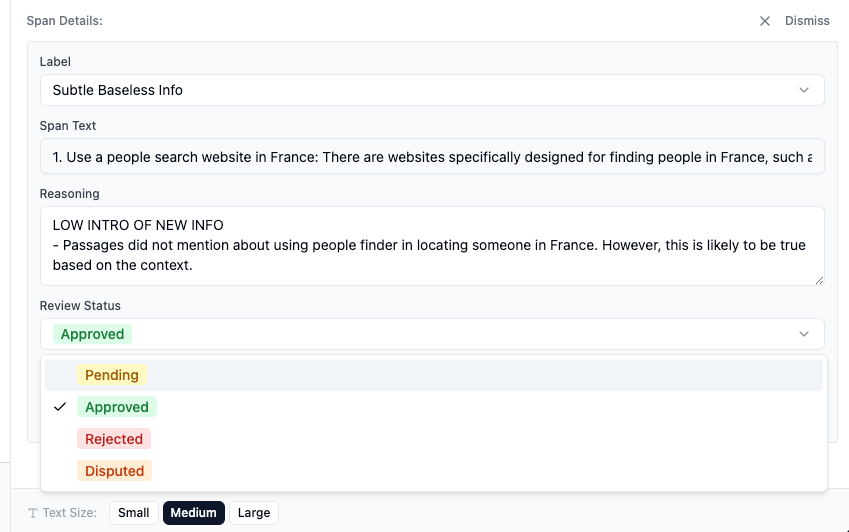
"meta": "LOW INTRODUCTION OF NEW INFORMATION\nThis specific detail about Anne's diary was not mentioned in the source content.",
"label_type": "Subtle Baseless Info"
}
]RAGTruth Dataset Characteristics
Task Distribution
The 408 datapoints we worked with consisted of:
- 174 Summary tasks (like the example above)
- 234 QA tasks (e.g., "Briefly answer the following question: how to boil potatoes for easy peeling. Bear in mind that your response should be strictly based on the following three passages...")

Model Distribution
The models used to generate responses were equally distributed (68 datapoints each):
- llama-2-70b-chat
- llama-2-13b-chat
- llama-2-7b-chat
- mistral-7B-instruct
- gpt-3.5-turbo-0613
- gpt-4-0613
Original Annotation Statistics
The original RAGTruth annotators identified a total of 86 hallucinations in the 408 datapoints we examined. This translates to:
- Average hallucinations per response: 0.21
- Hallucination rate (proportion of datapoints with at least one hallucination): 15.9%
- Hallucination-free responses: 84.1%
Labelground: Our Annotation Tool
To work on this and similar datasets, we decided to build a tool that enables us to efficiently review, alter, and complete span-level annotations.
Key Features:
Labelground provides a split-view interface where the prompt and context are displayed on the left side, and the LLM's response is displayed on the right. All annotations are highlighted in the text.
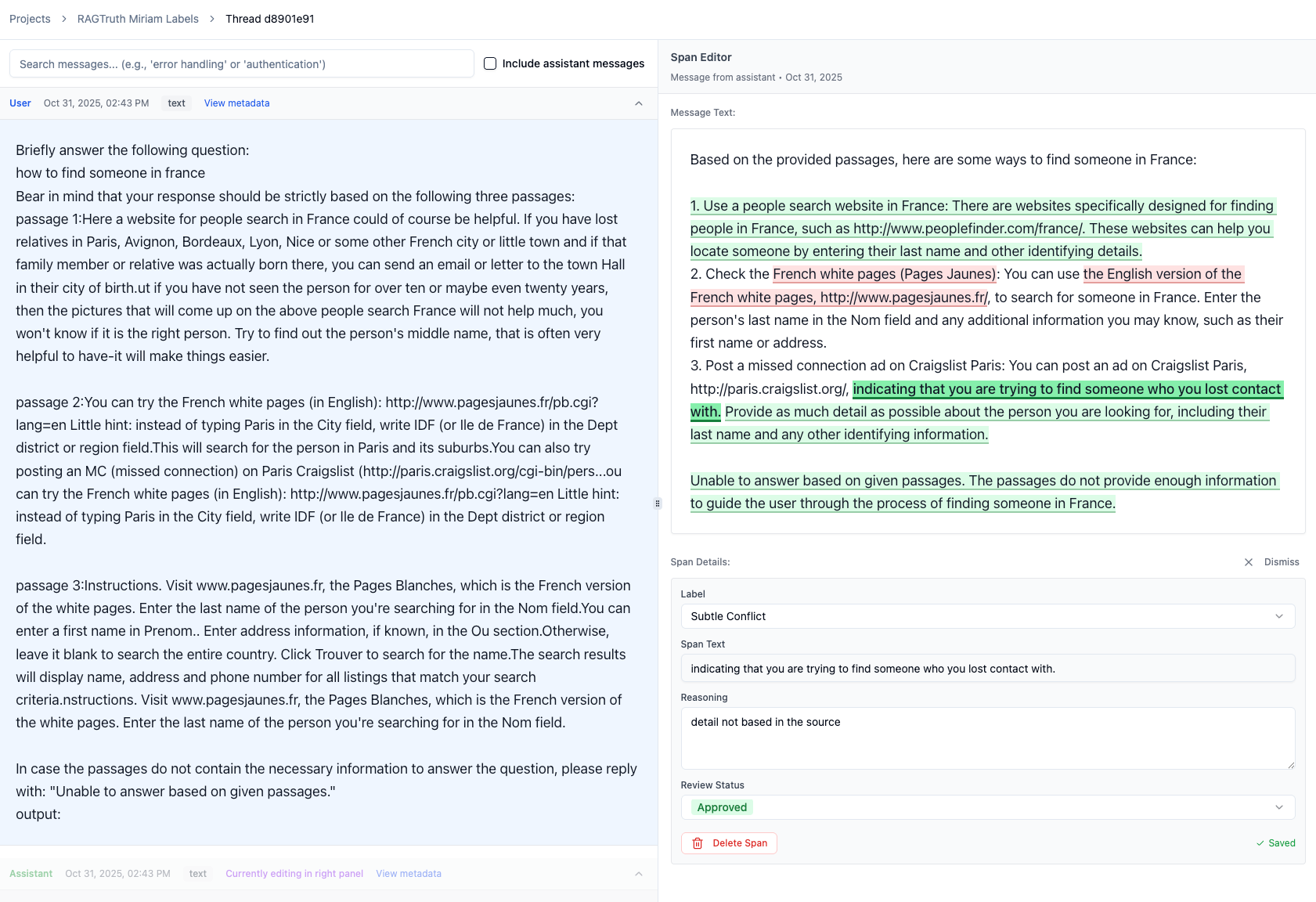
For each annotation, you can:
- Approve it (confirm it's a hallucination)
- Reject it
- Mark it as "Disputed" and return to it later
- Adjust the text span or classification
You can also mark any text span and create a new annotation at any time.
The Annotation Process
With Labelground built, we began the process of creating RAGTruth++. This involved three main phases: automatic detection, independent human annotation, and consensus building.
Phase 1: Automatic Hallucination Detection
Before beginning human annotation, we ran our automated Blue Guardrails detection method on all 408 datapoints. This method scans the prompts and generated responses and identifies spans with a high likelihood of being a hallucination, creating a set of predicted annotations.
The dataset was then loaded into Labelground with two types of annotations for human review:
- Original RAGTruth human annotations
- Blue Guardrails automatic predictions
Phase 2: Independent Human Annotation
Two human annotators (Mathis and Miriam from Blue Guardrails) independently reviewed every annotation and prediction. For each one, we either confirmed it, rejected it, or adjusted the span or its label. Additionally, we added any missing annotations we discovered during review.
Phase 3: Adjudication and Consensus
Inter-annotator agreement: The two annotators achieved an F1 score of 0.78, indicating substantial agreement.
Conflict resolution: For the 310 spans where our initial annotations disagreed, we met to discuss each case. Through this adjudication process, we reached consensus on all disputed spans.
Final gold standard: This systematic process resulted in our final RAGTruth++ annotations.
Introducing RAGTruth++
Comparative Overview
The table below shows a dramatic increase in detected hallucinations between RAGTruth and RAGTruth++. While the dataset size remained constant at 408 datapoints, the total number of annotated hallucinations increased from 86 to 865 (a 1005.8% increase). This translates to an average of 2.12 hallucinations per response in RAGTruth++ compared to just 0.21 in the original dataset, with the hallucination rate jumping from 15.90% to 74.75%.
| Metric | RAGTruth | RAGTruth++ | Increase |
|---|---|---|---|
| Total number of datapoints | 408 | 408 | - |
| Total hallucinations annotated | 86 | 865 | + 1005.8% |
| Average hallucinations per response | 0.21 | 2.12 | + 1009.5% |
| Hallucination rate | 15.90% | 74.75% | + 470.1% |
Hallucination Frequency by Model
The increase in detected hallucinations was consistent across all models, with each showing significant gaps in the original annotations:
- llama-2-7b-chat: 27 to 227 hallucinations
- llama-2-13b-chat: 13 to 194 hallucinations
- llama-2-70b-chat: 10 to 153 hallucinations
- mistral-7B-instruct: 35 to 142 hallucinations
- gpt-4-0613: 0 to 83 hallucinations
- gpt-3.5-turbo-0613: 1 to 66 hallucinations
The smaller open-source models (llama-2-7b-chat and llama-2-13b-chat) had the highest absolute numbers of hallucinations in RAGTruth++, while gpt-4 and gpt-3.5-turbo had the fewest. Notably, gpt-4 went from zero annotated hallucinations in the original dataset to 83 in RAGTruth++, revealing that even the best-performing model had missed issues.

Conclusion
Limitations
The RAGTruth++ dataset has some limitations: First, 408 datapoints is rather small for a benchmarking dataset. Also, as outlined in our previous blog post, the tasks posed to the LLMs are very easy and do not reflect realistic challenges.
As is natural in the AI field, the models used to generate these responses are largely outdated at this point, and most modern LLMs would likely make slightly fewer and different types of mistakes.
Additionally, the density of hallucinations is very high: 74.75% of all datapoints contain at least one hallucination. Depending on which detection method you're benchmarking, this class imbalance could lead to an effect called base rate fallacy: a model can appear to perform well simply by predicting true positives every time.
The Value of RAGTruth++
Despite these limitations, we managed to enhance a popular high-quality benchmark dataset by making it more complete and reducing the number of false negatives.
The process of reviewing thousands of annotations has sharpened our ability to spot subtle hallucinations which is exactly the skill needed when auditing real-world AI applications.
RAGTruth++ addresses a real gap in the available benchmarks. While the original RAGTruth provided a foundation, the inaccurately low hallucination rate (15.9%) meant that many detection methods could achieve high scores without actually being effective.
The systematic annotation process we developed (combining automated detection, independent human review, and adjudication) can be applied to other datasets. We built Labelground specifically to make this workflow efficient and repeatable.
To tackle hallucinations seriously, high-quality benchmarks are necessary. We found a reliable, effective, efficient way of benchmarking hallucination detection approaches, and we're making it available to the community.
Get RAGTruth++
Feel free to use RAGTruth++ and let us know how it works for you.
Download: Available on HuggingFace.
Learn more: Watch Mathis' video for more in-depth information on how RAGTruth++ was created.
This work was conducted by Miriam and Mathis, founders of Blue Guardrails, as part of our mission to help teams build AI responsibly.
Would you like to receive more content like this?
Subscribe to our email list
